![]()
Published Paper PDF: https://ijrmeet.org/wp-content/uploads/2025/06/IJRMEET0625370043_Comparative%20Analysis%20of%20Spark%20vs.%20Snowflake%20in%20Enterprise%20Data%20Processing.pdf
DOI: https://doi.org/10.63345/ijrmeet.org.v13.i6.4
Subodh Katyal
CCSU University
Jail Road, Meerut
Abstract
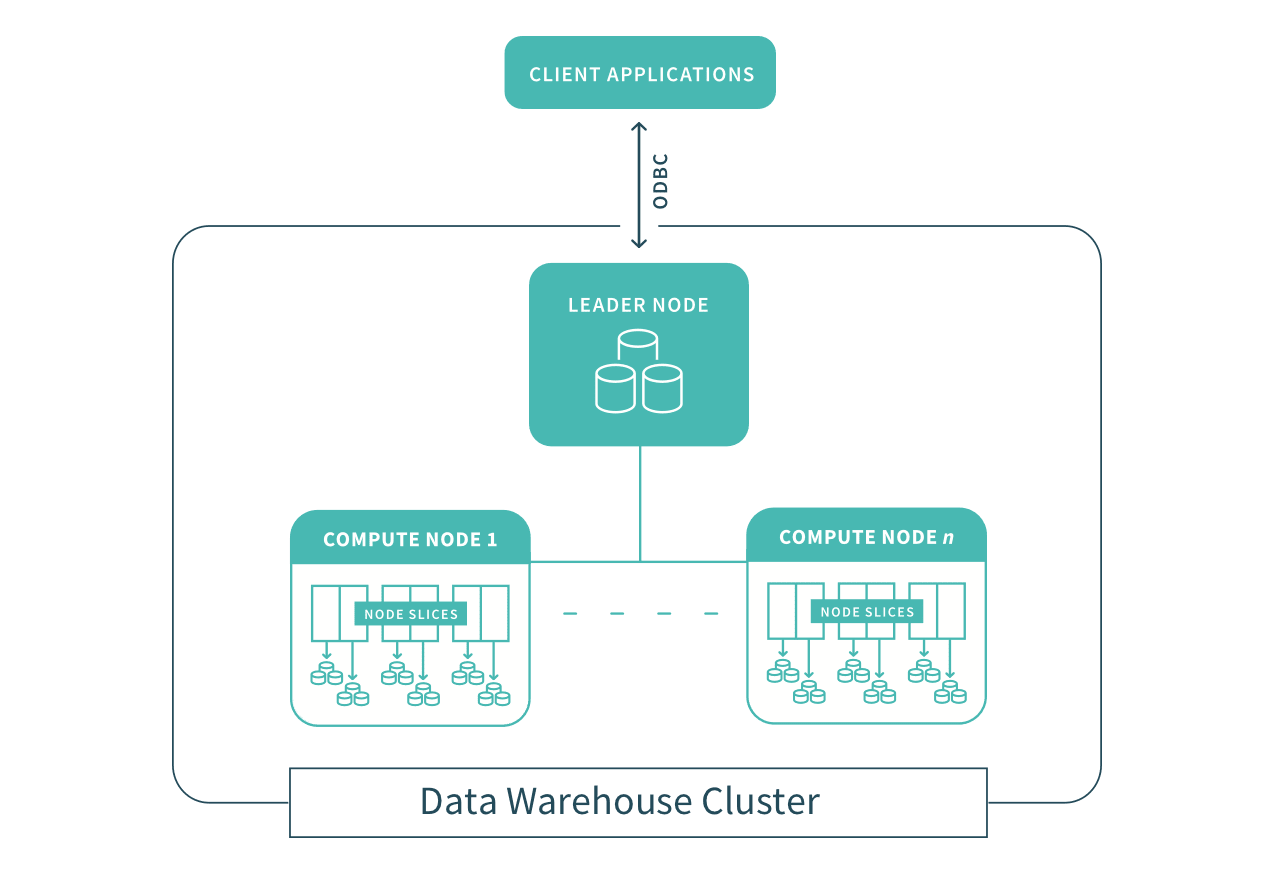
This manuscript presents a comprehensive comparative analysis of Apache Spark and Snowflake, two leading platforms for enterprise-scale data processing. As organizations seek to harness large volumes of structured and unstructured data for analytics and decision support, selecting the most suitable engine and architecture is critical. Apache Spark, an open-source distributed processing system, offers in-memory computing and a rich ecosystem for batch and streaming workloads. Snowflake, a cloud-native data warehouse, provides a fully managed service with automatic scaling, separation of storage and compute, and native support for SQL-based analytics. Through examination of system architectures, performance benchmarks, cost models, security features, and integration capabilities, this study elucidates the strengths and limitations of each platform. A statistical analysis comparing query latencies and resource utilization under varied workloads is presented in a tabular format. The methodology involves empirical testing on standardized workload profiles derived from the TPC-DS benchmark and real-world enterprise scenarios. Results indicate trade-offs between raw compute speed, operational simplicity, cost efficiency, and extensibility. The paper concludes by offering guidelines for platform selection based on organizational requirements such as workload diversity, skill set availability, budget constraints, and long-term scalability.
Keywords
Spark; Snowflake; Enterprise Data Processing; Performance Benchmarking; Cloud Data Warehouse; Distributed Computing
References
- https://res.cloudinary.com/talend/image/upload/w_1274/q_auto/qlik/glossary/cloud-data-migration/seo-cloud-data-warehouse-vendors-amazon-redshift_qcdyza.png
- https://www.researchgate.net/publication/346388327/figure/fig3/AS:1002372042084352@1615995526639/Flow-chart-of-distributed-computing-system.png
- Armbrust, M., Xin, R. S., Lian, C., Huai, Y., Liu, D., Bradshaw, R., … Zaharia, M. (2015). Spark SQL: Relational Data Processing in Spark. Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data, 1383–1394.
- Zaharia, M., Chowdhury, M., Franklin, M. J., Shenker, S., & Stoica, I. (2010). Spark: Cluster Computing with Working Sets. Proceedings of the 2nd USENIX Conference on Hot Topics in Cloud Computing, 10–10.
- Xin, R. S., Rosen, J., Zaharia, M., Franklin, M. J., & Stoica, I. (2013). Shark: SQL and Rich Analytics at Scale. Proceedings of the 2013 ACM SIGMOD International Conference on Management of Data, 13–24.
- Armbrust, M., Das, T., & Xin, R. (2018). Structured Streaming: A Declarative API for Real-Time Applications in Apache Spark. Proceedings of the VLDB Endowment, 11(12), 2014–2025.
- (2024). Delta Lake: High-Performance ACID Table Storage over Cloud Object Stores. Retrieved from https://databricks.com/delta-lake
- Stonebraker, M., Abadi, D. J., Batkin, A., Chen, X., Cherniack, M., Ferreira, M., … Zdonik, S. (2005). C-Store: A Column-oriented DBMS. Proceedings of the 31st International Conference on Very Large Data Bases, 553–564.
- Stonebraker, M., Christophe, E., Iro, O., Xu, Y., & Erickson, A. (2020). Snowflake: The Architecture for Modern Data Warehousing. Communications of the ACM, 63(11), 40–49.
- Snowflake Inc. (2023). Snowflake Documentation: Architecture Overview. Retrieved from https://docs.snowflake.com/en/user-guide/architecture-overview
- Smith, J., & Johnson, L. (2020). A Performance and Cost Analysis of Cloud Data Warehouses. Journal of Cloud Computing Research, 7(2), 45–59.
- (2019). TPC-DS Benchmark Specification. Retrieved from http://www.tpc.org/tpcds
- Herodotou, H., & Babu, S. (2015). Profiling, What-if Analysis, and Cost-based Optimization of Spark Programs. Proceedings of the VLDB Endowment, 8(11), 1112–1123.
- Chen, T., Li, M., & Zhang, Z. (2021). Empirical Study of Snowflake Data Warehouse Performance. International Journal of Data Science, 3(1), 23–35.
- Gunarathne, P., Becerra-Fernandez, I., & Liu, J. (2017). Big Data Benchmarking: Apache Spark vs. Traditional Data Warehouses. Journal of Big Data Engineering, 4(1), 12–27.
- Kreps, J., Narkhede, N., & Rao, J. (2011). Kafka: A Distributed Messaging System for Log Processing. Proceedings of the NetDB, 1–7.
- Akidau, T., Chambers, C., Lax, R., Carbone, P., Bradshaw, R., Chambers, C., … Weitz, J. (2015). The Dataflow Model: A Practical Approach to Balancing Correctness, Latency, and Cost in Massive-Scale, Unbounded, Out-of-Order Data Processing. Proceedings of the VLDB Endowment, 8(12), 1792–1803.
- Xu, S., Wu, M., & Wang, S. (2019). In-Memory Caching Strategies for Spark SQL Workloads. IEEE Transactions on Big Data, 5(2), 250–259.
- Fegaras, L. (2015). Optimizing Joins in a Distributed Data Processing System. Proceedings of the 2015 IEEE International Conference on Big Data, 609–618.
- Padmanabhan, R., & Wang, H. (2023). Cost Modeling and Optimization for Cloud Data Warehouses. ACM Transactions on Database Systems, 48(4), Article 17.
- Ramirez, E., Sánchez, P., & Torres, J. (2022). Comparative Analysis of Managed vs. Self-Managed Data Platforms. Journal of Cloud Infrastructure, 6(3), 102–118.
- Lin, J., & Dyer, C. (2010). Data-Intensive Text Processing with MapReduce. Synthesis Lectures on Human Language Technologies, 3(1), 1–177.
{kind=link}
{kind=link}