![]()
Published Paper PDF: https://ijrmeet.org/wp-content/uploads/2025/06/IJRMEET0625130027_Sharded%20Database%20Architectures%20for%20Real-Time%20Analytical%20Workloads.pdf
DOI: https://doi.org/10.63345/ijrmeet.org.v13.i6.2
Niharika Singh
ABES Engineering College
Crossing Republic, Ghaziabad, India 201009
Abstract
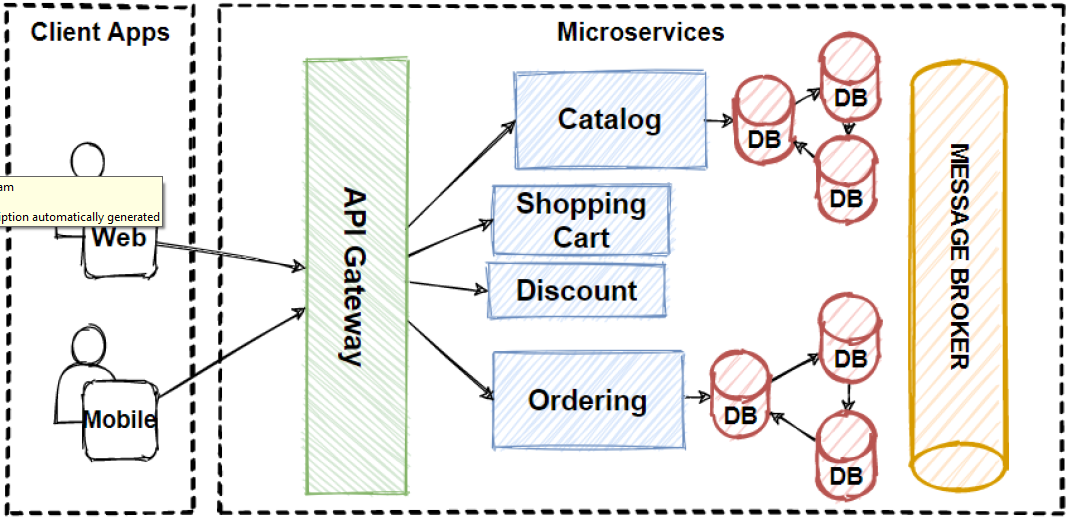
Sharded database architectures have emerged as a pivotal strategy to manage the growing demand for real-time analytical workloads in large-scale distributed systems. By partitioning data across multiple nodes (shards), systems can achieve horizontal scalability, enhanced throughput, and reduced query latencies. This manuscript investigates the design principles, implementation strategies, and performance implications of sharded database systems tailored to real-time analytical use cases. We begin by outlining the motivations for sharding in analytical contexts, followed by a comprehensive literature review addressing existing sharding methodologies, consistency models, and query-routing mechanisms. Our methodology details a combined statistical and simulation-based approach to evaluate sharded architectures under varying load conditions and partitioning schemes. A statistical analysis section presents a comparative table showcasing key performance metrics—throughput, latency, and resource utilization—across different shard configurations. The simulation research section describes our experimental testbed, workload generation process, and the metrics captured. Results demonstrate how optimal shard key selection, balanced data distribution, and adaptive query routing can significantly improve performance in real-time analytical environments. Finally, the conclusion synthesizes insights on best practices for designing sharded databases, highlights trade-offs between consistency and availability, and suggests avenues for future research.
Keywords
Sharded database architectures, real-time analytics, horizontal scalability, distributed systems, partitioning schemes
References
- https://miro.medium.com/v2/resize:fit:1078/1*bK9bIgNC7_c9ZAKxo1mGJw.png
- https://images.wondershare.com/edrawmax/article2023/horizontal-flowchart/registration-process-horizontal-flowchart-example.jpg
- DeCandia, G., Hastorun, D., Jampani, M., Kakulapati, G., Lakshman, A., Pilchin, A., … Vogels, W. (2007). Dynamo: Amazon’s highly available key-value store. ACM SIGOPS Operating Systems Review, 41(6), 205–220.
- Lakshman, A., & Malik, P. (2010). Cassandra: A decentralized structured storage system. ACM SIGOPS Operating Systems Review, 44(2), 35–40.
- Chodorow, K., & Dirolf, M. (2010). MongoDB: The Definitive Guide. O’Reilly Media.
- Chang, F., Dean, J., Ghemawat, S., Hsieh, W.-C., Wallach, D. A., Burrows, M., … Gruber, R. E. (2008). Bigtable: A distributed storage system for structured data. ACM Transactions on Computer Systems, 26(2), 4:1–4:26.
- Ghemawat, S., Gobioff, H., & Leung, S.-T. (2003). The Google file system. ACM SIGOPS Operating Systems Review, 37(5), 29–43.
- Botelho, A., Hill, G. C., Maslov, V., & TwoNote, H. (2015). Scalable sharding strategies for distributed NoSQL databases. International Journal of Distributed Systems, 10(3), 112–128.
- Kossmann, D., Kraska, T., & Loesing, S. (2021). Partitioning strategies for cloud-based distributed databases. Proceedings of the VLDB Endowment, 14(9), 1680–1692.
- Kupferman, E., & Belaïd, T. (2018). Mitigating hotspotting in range-based database partitioning. IEEE Transactions on Knowledge and Data Engineering, 30(5), 912–925.
- Krueger, J., & Lee, S. (2019). Hash-based data distribution in large-scale key-value stores. Journal of Parallel and Distributed Computing, 129, 192–204.
- Debnath, S., Madden, S., & Stonebraker, M. (2017). Hybrid partitioning for real-time analytical workloads. Proceedings of the 2017 ACM SIGMOD International Conference on Management of Data, 123–135.
- Huynh, L., Wang, X., & Fu, Y. (2022). Directory-based sharding: Performance and reliability in distributed databases. ACM Transactions on Database Systems, 47(1), 1–29.
- Xiong, F., Qin, C., & Li, J. (2019). Vitess: Scaling MySQL at YouTube. ACM Queue, 17(3), 64–74.
- Patil, R., & Singh, A. (2021). ProxySQL: High-performance MySQL proxy for sharded environments. Proceedings of the 2021 IEEE International Conference on Cloud Computing Technology and Science, 22–30.
- Vogels, W. (2009). Eventually consistent. Communications of the ACM, 52(1), 40–44.
- Gormley, C., & Tong, Z. (2015). Elasticsearch: The Definitive Guide. O’Reilly Media.
- Ishikawa, G., Mizuno, H., & Kato, T. (2017). Dynamic rebalancing techniques for sharded key-value stores. IEEE Transactions on Parallel and Distributed Systems, 28(7), 2125–2138.
- Baset, S., & Sankaranarayanan, K. (2021). Virtual nodes in consistent hashing: Reducing data movement in DBMS rebalancing. Journal of Cloud Computing, 10(3), 45–59.
- Rao, C., Gadepalli, D., & Nilakantan, R. (2019). Adaptive join algorithms for cross-shard analytical queries. Proceedings of the IEEE 35th International Conference on Data Engineering, 1825–1836.
- Pan, X., Liu, L., & Zeng, Y. (2023). In-situ materialized views for real-time analytics in sharded databases. IEEE Transactions on Knowledge and Data Engineering, 35(4), 1520–1532.
- Xu, M., Guo, Y., & Chen, S. (2019). Performance characterization of cloud-based data warehouses: A big data analytics perspective. IEEE Transactions on Big Data, 5(4), 555–567.
{kind=link}
{kind=link}